Tabelas em Movimento
Alguns Desafios e Continuidades entre Batch e Streaming Data
Introdução
 Esse artigo surgiu como uma curiosidade analítica. Lendo um importante livro de engenharia de dados me deparei com uma breve discussão sobre “modelagem de dados em tempo real” — era umas duas páginas mais ou menos, um livro de 300 páginas. Não é uma crítica, apenas um dado sobre o contexto dessa discussão.
Esse artigo surgiu como uma curiosidade analítica. Lendo um importante livro de engenharia de dados me deparei com uma breve discussão sobre “modelagem de dados em tempo real” — era umas duas páginas mais ou menos, um livro de 300 páginas. Não é uma crítica, apenas um dado sobre o contexto dessa discussão.
A despeito de uma seção bastante interessante com vários pontos levantados, uma afirmação em questão foi a que mais me chamou atenção: a de que é praticamente impossível aplicar técnicas de modelagem tradicional — associadas a ideia de batch na discussão — em dados em tempo real. Mas será mesmo que são dados analiticamente tão diferentes assim? Esses dados são tão diferentes assim dos dados produzidos em modelo batch?
Um exemplo de aproximação abstrata, porém direta, encontramos na arquitetura do Spark Streaming. A stream de dados (DStream) é, por baixo do capô, uma sequência de RDDs. Ou seja, uma composição de mini-batches conformam uma stream.
Talvez faça sentido mais pensar em OLTP vs. OLAP, nessa dicotomia parecem residir as maiores diferenças de requisitos do ponto de vista de dados e modelagem. Não na dicotomia batch vs. tempo real, mas transações vs analytics. As necessidades do transacional geralmente demandam menos latency que a do analytics, só pra inicio de conversa.
Em algum momento os dados, mesmo em tempo real, vão precisar de alguma lógica, algum formato que facilitará e conferirá consistência e confiabilidade às visualizações, análises e tomadas de decisão automatizadas. Afinal, dados só fazem sentido se falarem algo sobre a realidade, e, para isso, precisam representá-la — portanto, precisam de alguma modelagem.
Em cenários “tradicionais” de data warehouse, com pipelines em batch, rodando “tranquilamente” desde sempre por aí, conhecemos as boas práticas e técnicas de modelagem de dados mais difundidas pelo mercado, que dão mais certo e que são praticamente padrões, basicamente a dimensional e o data vault. Mas e em um cenário de dados real-time ou near-real-time? Já se perguntou como isso acontece? Como fica a modelagem de dados se o fluxo de dados for realmente constante e incessante?
Esse artigo é resultado de uma busca por trazer um pouco de clareza para questões como essas. Dados em tempo real significam, em uma só palavra: dinamicidade. Mesmo que esse tempo real tenha delay de alguns segundos, a velocidade é razoavelmente alta para ser considerada dimensão estratégica de negócios contemporaneamente. Por exemplo, em casos de fraude financeira, um sistema com decisões e flags automatizadas em quase real time de pouquissimos segundos é game-changer.
Dinamicidade

Fluxos cada vez mais próximos ao tempo real não querem dizer apenas dados mais rápidos. A natureza do dado também é mais dinâmica, a gestão de alterações/evoluções na estrutura dos dados passam a ser maiores e mais necessárias.
Arrisco a dizer que, quase que de maneira geral, quanto maior volume e velocidade (mais próximo do real time) mais a engenharia de dados se beneficia de boas práticas de engenharia de software e automações em diferentes componentes dos pipelines — monitoramento, quality, contracts, schema-evolution, etc.
Seja em um cenário puro batch ou com algo mais próximo ao real time, acurácia e consistência são fundamentais — esses atributos são definitivamente bastante definidos pela modelagem de dados. Como lidar com isso em cenários real time? A saída para questões do tipo: “como modelar dados em tempo real”? está bastante atrelada à arquitetura da solução, e não só exclusivamente reservado ao ato de “modelar” os dados ao decorrer do fluxo. Em janelas analíticas, por exemplo.
Do ponto de vista da arquitetura, em algum momento o conceito de arquitetura lambda possivelmente será ativado — ou algo similar. A prática e a literatura mostram algo parecido: o dado em tempo real está mais para ser monitorado do que modelado, contudo, em algum ponto do analytics alguma modelagem se fará necessária, e aqui pode parecer que nos aproximamos do mundo batch novamente. O que faz levantar a perguntar, será que a dicotomia batch/realtime é um bom ponto de partida para pensar na modelagem? Meu palpite é de que talvez nem tanto. Mas não é por isso que esse ponto deixa de fazer sentido e levanta bons pontos críticos aos praticantes.
 Mesmo que não seja um ponto de partida perfeito, muitas vezes, na engenharia de dados essa discussão sobre modelagem de dados em tempo real acaba caindo num debate tempo real vs. datawarehouse porque de fato a dimensão volume no tempo é fundamental nestas questões e a modelagem mais tradicional é mais estática.
Mesmo que não seja um ponto de partida perfeito, muitas vezes, na engenharia de dados essa discussão sobre modelagem de dados em tempo real acaba caindo num debate tempo real vs. datawarehouse porque de fato a dimensão volume no tempo é fundamental nestas questões e a modelagem mais tradicional é mais estática.
Por outro lado, esses mundos estão cada vez mais próximos. Atualmente, contamos no mercado, com uma tendência que aponta diretamente para plataformas de datawarehouse que são capazes de lidar com workload realtime. Unindo os dois mundos em plataformas RTDW.
Já que datawarehousing demanda uma certa solução arquitetural especifica, por que não deslocamos a conversa um pouco para esse ponto de uma modelagem que considera a arquitetura também?
Mesmo para um ambiente full tempo real, com práticas de monitoramento nas variações das streams, dificilmente deixará de existir um ambiente “rest” ou em batch que o complementa. Dificilmente os usuários não irão necessitar de análises de dados históricos. Sendo assim, como proceder? Qual é o pulo do gato para melhor gerir e compreender os dados do real time? Tem diferença?
Uma saída, como supramencionado, é pensar a modelagem dos dados associada à arquitetura que sustenta as operações. Nesse caso, tudo tem uma semântica própria e específica. E isolar cada componente pode não ser a melhor solução. Antes, buscar uma visão mais holística de como todos os dados estão chegando e estão servindo ao business é mais estratégico e tende a gerar melhores resultados. Afinal, cada stream tem a chance de ser, em alguma outra parte da arquitetura, uma tabela, e vice-versa.
Onde acaba a stream e começa uma table definitivamente? Talvez essa definição nunca será tão clara como nossas mentes racionais e um tanto perfeccionistas gostariam em muitos momentos.
Como proceder nesses casos, aplicamos técnicas específicas para esses cenários? Faz sentido pensar em termos mais associados ao mundo batch, como por exemplo a modelagem dimensional de Kimball?
Até aqui, discutimos as diferenças fundamentais entre dados batch e dados em tempo real, destacando como cada abordagem tem seu lugar nas arquiteturas modernas de dados. Observamos que a arquitetura Lambda frequentemente se torna um ponto de convergência entre essas duas abordagens, proporcionando uma solução híbrida que tira proveito tanto do processamento em batch quanto do processamento em tempo real.
Com isso em mente, é crucial entender como a modelagem de dados, tradicionalmente aplicada em cenários batch, pode ser adaptada e integrada para suportar as exigências de dados em tempo real. Essa adaptação requer não apenas uma mudança nas técnicas de modelagem, mas também uma consideração cuidadosa da arquitetura subjacente que sustenta as operações de dados. Afinal performance é fundamental.
Antes de falar propriamente de tempo real, vamos relembrar a ideia de modelagem de dados.
Modelagem de Dados
Boa parte da Modelagem de dados é o processo de criação de uma representação abstrata dos dados e suas relações dentro de um determinado domínio ou contexto. Esta representação facilita a compreensão, manipulação, análise e visualização dos dados pois fornece uma base comum de significado a respeito dos dados e a respeito do que os dados representam sobre a realidade em si.

Podemos entendê-la como a prática de definir e estruturar os dados de forma que possam ser facilmente compreendidos, manipulados e analisados. O que envolve a criação de diagramas ou esquemas que descrevem as entidades de interesse, os atributos dessas entidades e os relacionamentos entre elas com o objetivo de facilitar a gestão e o uso dos dados, garantir regras para a integridade e a qualidade dos dados, e fornecer uma base consistente para a implementação de sistemas de informação.
As diferentes dimensões da modelagem são a conceitual, a lógica e física, e seus componentes principais são as entidades, os atributos, os relacionamentos e as chaves. Aplicações mais comuns são bancos de dados, sistemas gerais de informação e análise de dados.
Seus desafios geralmente passam pela complexidade, escalabilidade de mudança nos dados. Sendo a complexidade relacionada a representação compreensível e gerenciável dos diferentes domínios de dados de um contexto mais amplo (empresa, por exemplo), a escalabilidade relacionada ao suporte no aumento dos volumes de dados e a mudança nos dados relacionado as mudanças nos requisitos e ambiente de negócios que levam, necessariamente, a alteração nos modelos.
Não é preciso enfatizar que a modelagem de dados é um processo crítico na ciência da computação e na gestão da informação — e não restrita à engenheria de dados — pois fornece a estrutura necessária para armazenar, organizar e utilizar dados de maneira eficaz.
Portanto, a aplicação de técnicas de modelagem de dados busca garantir que as informações produzidas a partir daqueles esquemas sejam precisas, consistentes e úteis para suportar as operações e decisões organizacionais. E em tempo real, isso muda? Ou por que teria de mudar?
A modelagem de dados “tradicional” tende a ser mais voltada para dados históricos ou estáticos, enquanto o monitoramento de dados se concentra nos dados em tempo real. Isso não significa que a modelagem de dados históricos se tornará obsoleta; pelo contrário, ela continuará desempenhando um papel fundamental na análise retrospectiva e na tomada de decisões estratégicas.
Ou seja, há forte complementaridade entre a modelagem de dados históricos e o monitoramento de dados em tempo real, em vez de uma substituição completa. Além disso, em muitos casos, é possível adotar o modelo mental de modelagem de dados mais tradicionais em situações de consulta, por exemplo, para analisar dados em tempo real ainda sem estrutura.
Uma coisa interessante de lembrarmos é que muitas vezes quando lidamos com dados em batch, muitas vezes são logs de produção que não tem tanto volume ainda pra ler em tempo real. Dados que muitas vezes, em maior volume, são mais monitorados.
Modelagem de Dados em Tempo Real
No que diz respeito à práticas de modelagem em tempo real. As mais comumente mobilizadas são event streams. Neste caso, a modelagem pode se basear em pressupostos como modelagem baseada em janelas de tempo, events, criadas por materialized views ou até mesmo atualização via CDC.
A modelagem de dados em tempo real é fundamental para sistemas que precisam processar e analisar grandes volumes de dados à medida que eles são gerados. Vamos detalhar um pouco mais as técnicas mencionadas.
Event Streams como Tabelas
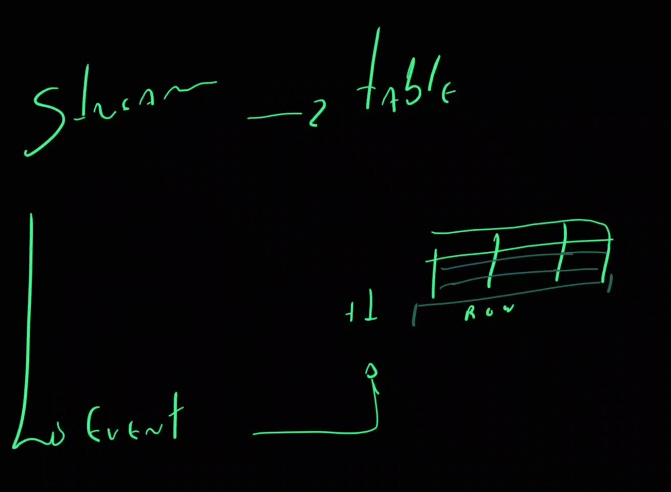
Essa abordagem permite tratar fluxos contínuos de eventos como se fossem tabelas em um banco de dados, facilitando a consulta e agregação dos dados. Algumas abordagens comuns são:
Modelagem Baseada em Janelas de Tempo
- Sliding Windows: A janela se move continuamente, considerando um período fixo de tempo para cada nova análise. Ideal para monitoramento contínuo.
- Tumbling Windows: Janelas de tempo fixas que não se sobrepõem. Cada evento pertence a uma única janela, útil para agregações periódicas como contagens diárias.
- Session Windows: Agrupam eventos baseados em sessões de atividade, onde a janela é determinada por períodos de inatividade.
Estados de Eventos e Processamento Incremental
- Estados Intermediários: Manter o estado dos dados em memória para cálculos contínuos.
- Processamento Incremental: Atualizações são feitas à medida que novos eventos chegam, recalculando apenas o que é necessário, o que é eficiente para grandes volumes de dados.
Materialized Views
São tabelas precomputadas que armazenam resultados de consultas frequentes ou complexas. As views são atualizadas com a chegada de novos dados, proporcionando respostas rápidas a consultas complexas.
Change Data Capture (CDC)
Técnica para capturar e aplicar mudanças em dados de sistemas de origem, refletindo essas mudanças em tempo real em sistemas de destino, como bancos de dados ou sistemas de streaming. Essencial para manter a sincronização entre diferentes sistemas.
Essas abordagens são fundamentais para sistemas que lidam com dados em tempo real, apoiando na eficiência, precisão e na escalabilidade para uma ampla gama de cenários de uso.
De um ponto de vista mais ferramental, é comum soluções bastante apoiadas em Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Beam, Google Dataflow, etc. Ferramentas especificamente preparadas para lidar com as cargas de trabalho de uma plataforma de streaming distribuída, armazenando e processando dados.
Na sequência, desdobramos um exemplo prático simples e didático, pra gente refletir um pouco mais sobre o que já falamos até aqui em cima de alguma referência mais “palpável”, em código.
Chega mais…
Exemplo Prático
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, col, count, first
import logging
#Configurando o nível de logging
logging.getLogger("py4j").setLevel(logging.ERROR)
#Criando a sessão do Spark
spark = SparkSession.builder \
.appName("StreamingDimensionalModelExample") \
.getOrCreate()
#Definindo o nível de logging do Spark
spark.sparkContext.setLogLevel("ERROR")
#Read stream from rate source
purchaseStream = spark.readStream \
.format("rate") \
.option("rowsPerSecond", 5) \
.load() \
.selectExpr("value as sale_id",
"CAST(value % 10 AS STRING) as product_id",
"CAST(value % 5 AS STRING) as customer_id",
"concat('Product', value % 10) as product_name",
"concat('Customer', value % 5) as customer_name",
"timestamp")
#Calculate sum of sales by product_id
sales_sum = purchaseStream.groupBy("product_id") \
.agg(count("sale_id").alias("total_sales"))
#Write the result to console
query = sales_sum.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", "false") \
.start()
query.awaitTermination()
The Event
{
"sale_id": "1",
"product_id": "1",
"customer_id": "1",
"product_name": "Product1",
"customer_name": "Customer1",
"timestamp": "2024-05-28T12:00:00"
}
Le Stream
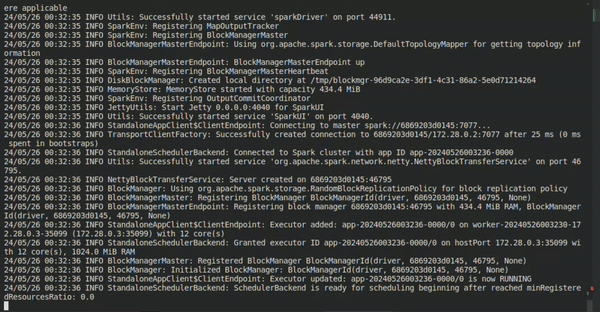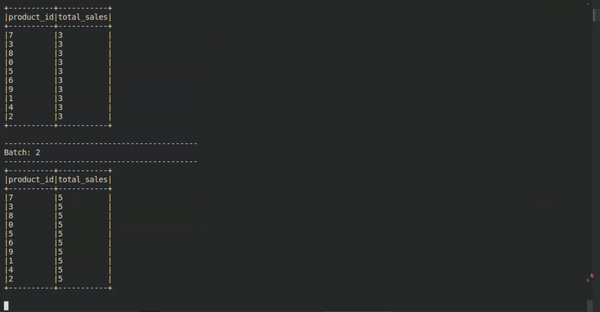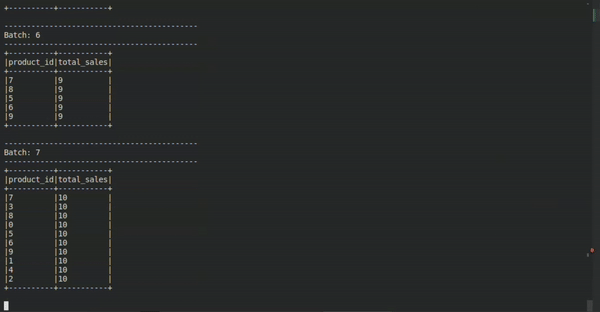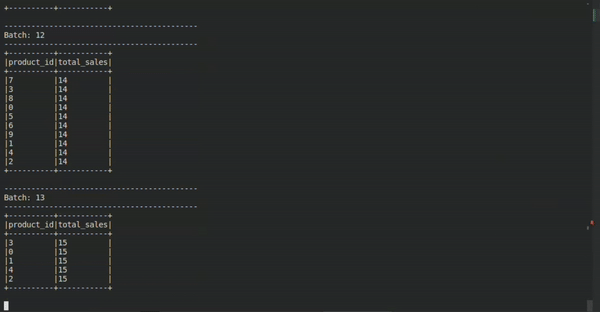
Neste exemplo bastante enxuto, nós podemos aplicar a mentalidade conhecida por meio da técnica Kimball, por exemplo. Algo que pode facilitar a vida do analista ou do engenheiro no momento em que precisar correlacionar/aplicar regras de negócio, ou com alguma modelagem já existente, por exemplo.
Podemos usar com certa liberdade as modelagens mais tradicionais mesmo que como modelos-mentais-mediadores para mediar o mundo estático e o mundo em fluxo. No caso em questão, recebe-se uma stream de tipo evento e modela-se esses dados para extrair o valor agregado da quantidade total de produtos vendidos por cada categoria de produto em tempo real.
Como isso acontece? Uma maneira de interpretar essa modelagem é percebendo a dimensão ‘produto’ e o fato ‘sale’ como concatenados em uma agreção vinda de uma stream evento (que a gente já entendeu que é tipo uma table em movimento).
The “batch” rationale (modeling)
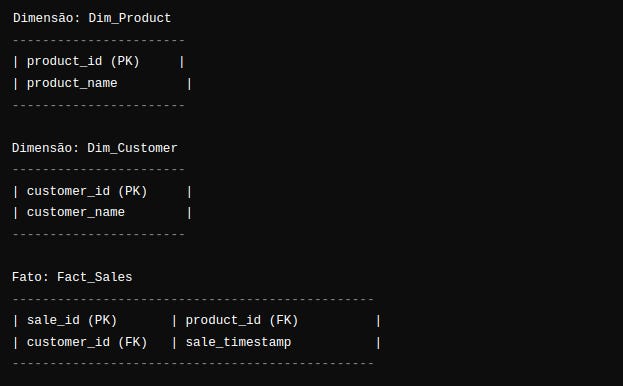
Vejam como nesta descrição nós conseguimos descrever razoavelmente uma possível modelagem do raciocínio que acontece por trás da query que mostra nosso resultado esperado no console.
É claro que não há como afirmar e muito menos garantir na prática que a modelagem relacional (de batch) sustenta a performance e escalabilidade em todo e qualquer sistema em tempo real.
Contudo, essa continuidade entre os mundos estático e em fluxo são reforçados com a tendência de datawarehouses que processam workload em tempo real, o que reforça em certa medida a necessidade de combinar o raciocínio da modelagem “tradicional” para facilitar o raciocínio analítico, mesmo que sem necessariamente criar uma modelagem completa e fechada em análises diretas de streams. Esses pontos podem dar pistas de que o futuro não será tão diferente assim em termos de modelagem de dados, mas é claro que as estratégias de arquitetura, armazenamento e processamento são diferentes e precisam ser consideras de acordo com cada contexto e requisitos específicos e merecem foco específico.
Considerações Finais
Pensar em termos relacionais ao analisar streams de dados não é incomum, especialmente quando se trata de integrar dados em tempo real com sistemas existentes que já adotam modelos relacionais, como bancos de dados relacionais ou data warehouses. No entanto, o grau em que a modelagem relacional é aplicada pode variar dependendo do contexto e dos requisitos específicos do projeto.
Aqui estão algumas situações em que pensar em termos relacionais ao analisar streams de dados pode ser mais comum:
- Integração com sistemas legados: Se você estiver integrando dados em tempo real com sistemas legados que utilizam bancos de dados relacionais, é natural pensar em termos relacionais para facilitar a integração e a comunicação entre os sistemas.
- Consistência com modelos existentes: Se a sua organização já possui modelos de dados relacionais estabelecidos para representar informações de negócios, pode fazer sentido aplicar uma abordagem relacional também ao lidar com streams de dados em tempo real, para manter a consistência e a familiaridade com os modelos existentes.
- Requisitos de análise complexa: Em alguns casos, pode ser necessário realizar análises complexas que se beneficiam das capacidades de modelagem relacional, como consultas envolvendo várias tabelas ou operações de join entre diferentes fontes de dados em tempo real.
Por outro lado, em cenários onde o foco está na análise de eventos e fluxos de dados em tempo real, pode ser mais eficaz adotar modelos de dados orientados a eventos ou fluxos de dados que se concentram na captura e análise de eventos individuais em vez de relações entre entidades.
Em resumo, pensar em termos relacionais ao analisar streams de dados pode ser beneficial em certos contextos, especialmente quando se trata de integração com sistemas existentes ou requisitos de análise complexa. No entanto, a abordagem mais adequada dependerá dos requisitos específicos do projeto, das tecnologias envolvidas e das preferências da organização em relação à modelagem de dados.
Referências
- Johanna Vainio. “Data Ingestion and Data Modeling for Business Real-time Processing”, 2024. https://www.agiledataengine.com/blog/data-ingestion-and-data-modeling-for-business-real-time-processing
- Joe Reis & Matt Housley. “Fundamentals of Data Engineering”. O’Reilly, 2022.
- Justin Hayes. “An Overview of Real Time Data Warehousing on Cloudera”, 2020. https://blog.cloudera.com/an-overview-of-real-time-data-warehousing-on-cloudera/
- Tyler Akidau, Slava Chernyak, and Reuven Lax. “Streaming Systems”. O’Reilly, 2018.
- Martin Kleppmann. “Designing Data-Intensive Applications”. O’Reilly, 2017.
- Nathan Marz e James Warren. "Big Data: Principles and Best Practices of Scalable Realtime Data Systems". 2015.
- Kenneth M. Anderson. "Lambda Architecture". CSCI 5828: Foundations of Software Engineering, 2014. https://home.cs.colorado.edu/~kena/classes/5828/f14/lectures/29-lambdaarchitecture.pdf
- Byron Ellis. “Real-time Analytics”. Wiley, 2014.
- Apache Flink Documentation https://nightlies.apache.org/flink/flink-docs-stable/
- Apache Kafka Documentation https://kafka.apache.org/documentation/
- Apache Spark Documentation https://spark.apache.org/docs/latest/streaming-programming-guide.html