MapReduce
The logic behind the model
Read in PortugueseMapReduce is a programming model developed by Google in 2004 to facilitate processing large volumes of data through distributed computing. Although the model was widely adopted through frameworks like Hadoop MapReduce, it is no longer the predominant standard even inside Google, which moved to more modern solutions. So, is it still worth studying this model?
Considering that MapReduce was one of the first truly scalable frameworks applied in production, it became a fundamental reference in the history of distributed processing. Because of that, there are still good reasons for data engineers to learn its concepts - not only for historical relevance, but also as a basis to understand modern architectures and tools like Apache Spark and Apache Beam.
- MapReduce introduced many fundamental concepts of distributed processing that are used by more modern technologies. Understanding MapReduce helps build a solid foundation for understanding how and why these technologies work.
- Knowing the concepts of mapping, redistribution, ordering, and reduction is crucial to understand how data are distributed and processed in parallel.
- Knowing the evolution of Big Data technologies from MapReduce to Spark can provide a better understanding of the challenges that were solved over time.
- MapReduce was a significant innovation in its time, and many concepts and techniques developed for it are still applicable and relevant.
- Many organizations may still have Hadoop infrastructures that use MapReduce. Knowledge of MapReduce allows working with and maintaining these legacy systems effectively.
- The ability to migrate or integrate MapReduce-based systems to more modern technologies can be a valuable skill.
- Knowledge in MapReduce can help identify and solve performance problems in systems that use this technology.
- Understanding MapReduce bottlenecks and optimizations can be useful for performance tuning tasks in any distributed data pipeline.
Now that you know it is worth studying MapReduce, how does it work?
The MapReduce architecture is composed of components or steps: users define a map function that processes input data and generate an intermediate key/value set that will later be "reduced" by a reduce function that aggregates all values associated with the same intermediate key. Different task types can benefit from this model.
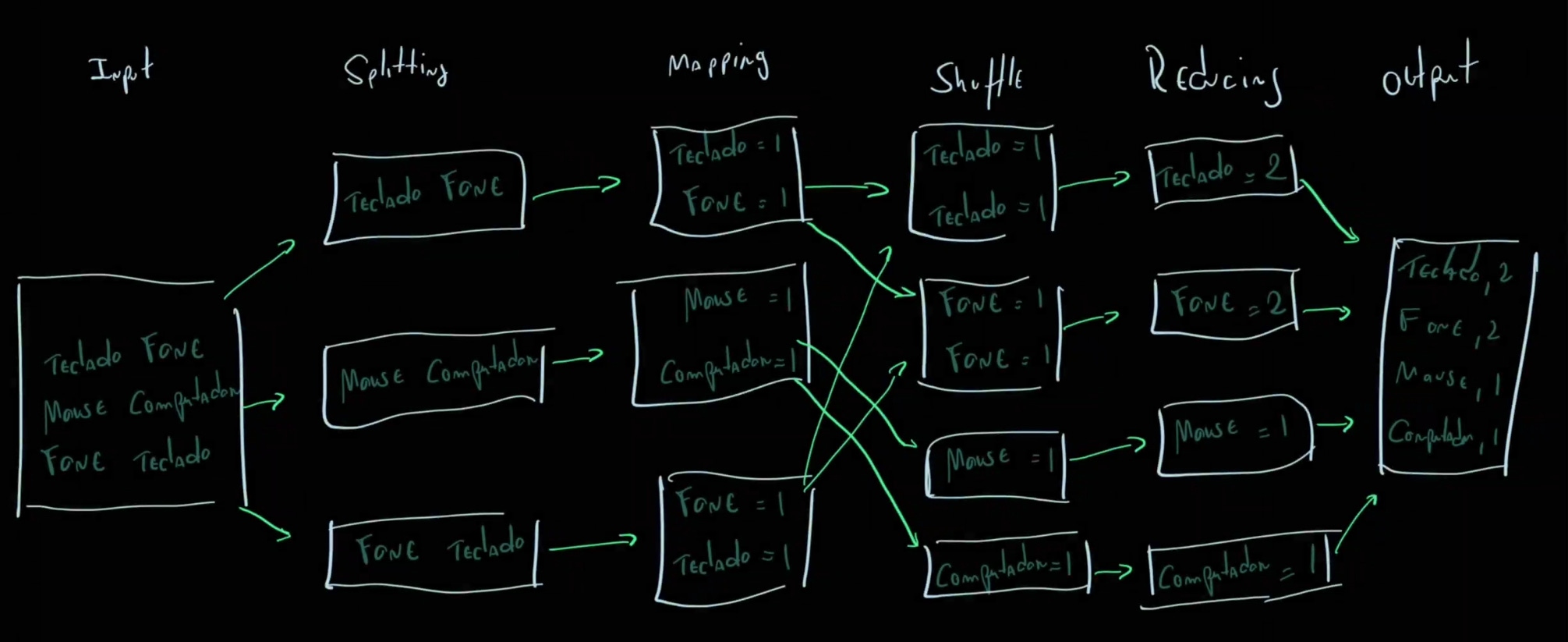
In general, we can consider 4 stages in how this programming model works. The first phase is splitting, which separates the initial input into different data chunks that will be processed in parallel. Next comes mapping, which we detailed above, followed by shuffle, which is a pre-reduce stage where workers redistribute data based on the keys resulting from the mapping phase. Finally, the reduce phase happens, also detailed in the previous paragraph.
Great, now let us understand all this a bit better with some Python code to make these concepts and flow easier to grasp.
To better understand MapReduce logic and architecture, we will implement a didactic case in Python simulating this method. We will not use the Mrjob library, used to run Hadoop MapReduce jobs, precisely so we can study these concepts in more detail.
Practical Example
from collections import defaultdict
import threading
#Function to split the text into several parts for parallel processing
def split_data(text, num_parts):
#Split the text into lines
lines = text.split("\n")
#Calculate the size of each chunk
chunk_size = len(lines) // num_parts
#Create a list of chunks with the calculated size
chunks = [lines[i * chunk_size: (i + 1) * chunk_size] for i in range(num_parts)]
#If there are leftover lines, add them as a last chunk
if len(lines) % num_parts != 0:
chunks.append(lines[num_parts * chunk_size:])
#Return the chunks
return chunks
#Mapping phase function (Map)
def map_phase(lines):
mapped = []
#For each line in the text chunk
for line in lines:
#Split the line into words
for word in line.split():
#Add each word as a tuple (word, 1) to the mapped list
mapped.append((word.lower(), 1))
return mapped
#Function executed by each mapping thread
def map_worker(text_chunk, results):
#Execute the mapping phase on the text chunk
mapped = map_phase(text_chunk)
#Add the mapping result to the results list
results.append(mapped)
#Function to collect and shuffle mapping results
def collect_and_shuffle(mapped_results):
shuffled = defaultdict(list)
#Iterate over each mapped result
for mapped in mapped_results:
#For each pair (key, value), add the value to the list for that key
for key, value in mapped:
shuffled[key].append(value)
return shuffled
#Function executed by each reduction thread
def reduce_worker(key, values, results):
#Compute the sum of values associated with a key
reduced_value = sum(values)
#Add the reduced result to the results dictionary
results[key] = reduced_value
#Main function that coordinates distributed MapReduce
def distributed_mapreduce(text, num_mappers, num_reducers):
#Split text into chunks for mappers
chunks = split_data(text, num_mappers)
#Mapping Phase
map_results = []
map_threads = []
for chunk in chunks:
#Create a thread for each data chunk
t = threading.Thread(target=map_worker, args=(chunk, map_results))
t.start()
map_threads.append(t)
#Wait for all mapping threads to finish
for thread_map in map_threads:
thread_map.join()
#Shuffle and sort phase
shuffled = collect_and_shuffle(map_results)
#Reduction Phase
reduce_results = {}
reduce_threads = []
for key, values in shuffled.items():
#Create a thread for each key to be reduced
t = threading.Thread(target=reduce_worker, args=(key, values, reduce_results))
t.start()
reduce_threads.append(t)
#Wait for all reduction threads to finish
for thread_reduce in reduce_threads:
thread_reduce.join()
# Return final results from the reduction phase
return reduce_results
#Test with a simple example
text = """hello world
this is a test, for studying mapreduce
hello world again, mapreduce again."""
if __name__ == "__main__":
#Run distributed MapReduce with 3 mappers and 3 reducers
result = distributed_mapreduce(text, num_mappers=3, num_reducers=3)
print(result)
Output

Explaining the code
Library imports
from collections import defaultdict: Imports defaultdict, a data structure that makes it easy to create dictionaries with default values.import threading: Imports the threading library to create and manage threads.
Functions
split_data
- Splits the text into lines using
text.split("\\n"). - Calculates chunk size based on the desired number of parts.
- Divides the text into chunks of approximately equal size.
- Returns the chunks as a list of strings.
map_phase
- Receives a list of lines.
- For each line, splits it into words and converts each word to lowercase.
- Returns a list of tuples
(word, 1)for each word found.
map_worker
- Executed by each mapping thread.
- Calls
map_phaseon the provided text chunk and adds the result to the results list.
collect_and_shuffle
- Collects mapping results into a defaultdict.
- Groups values associated with each key.
reduce_worker
- Executed by each reduction thread.
- Computes the sum of values associated with a key and stores the result.
distributed_mapreduce
Manages the whole distributed MapReduce process:
- Splits the text into chunks for mappers.
- Starts mapping threads to process each chunk.
- Waits for all mapping threads to finish.
- Collects and redistributes mapping results.
- Starts reduction threads to process each set of values associated with a key.
- Waits for all reduction threads to finish.
- Returns final results from the reduction phase.
Code test
- Scenario: A simple text example is processed using distributed_mapreduce with 3 mappers and 3 reducers.
- Input:
hello world this is a test, for studying mapreduce hello world again, mapreduce again. - Output:
{'hello': 2, 'world': 2, 'this': 1, 'is': 1, 'a': 1, 'test,': 1, 'for': 1, 'studying': 1, 'mapreduce': 2, 'again,': 1, 'again.': 1}
Final considerations
In this article we studied a simplified Python script that helps us understand the logic of this important distributed processing model implemented by Google in 2004 and considered a fundamental basis of distributed processing of large data volumes up to the present day.
References
- https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
- https://www.databricks.com/glossary/mapreduce
- https://ericcouto.wordpress.com/2013/06/06/mapreduce-python-parte-1/
- https://www.devmedia.com.br/big-data-mapreduce-na-pratica/32812
- https://medium.com/rodrigo-lampier/como-construir-um-programa-simples-de-mapreduce-2c8e6b0c2ccb
- https://medium.com/data-hackers/processamento-distribuido-de-dados-com-mapreduce-utilizando-python-mrjob-e-emr-c826a617f8b3